Abstract
We introduce Free3D, a simple approach designed for open-set novel view synthesis (NVS) from a single image.
Similar to Zero-1-to-3, we start from a pre-trained 2D image generator for generalization, and fine-tune it for NVS. Compared to recent and concurrent works, we obtain significant improvements without resorting to an explicit 3D representation, which is slow and memory-consuming.
We do so by encoding better the target camera pose via a new per-pixel ray conditioning normalization (RCN) layer. The latter injects camera pose information in the underlying 2D image generator by telling each pixel its specific viewing direction. We also improve multi-view consistency via a light-weight multi-view attention layer and multi-view noise sharing. We train Free3D on the Objaverse dataset and demonstrate excellent generalization to various new categories in several large new datasets, including OminiObject3D and Google Scanned Object (GSO).
Framework
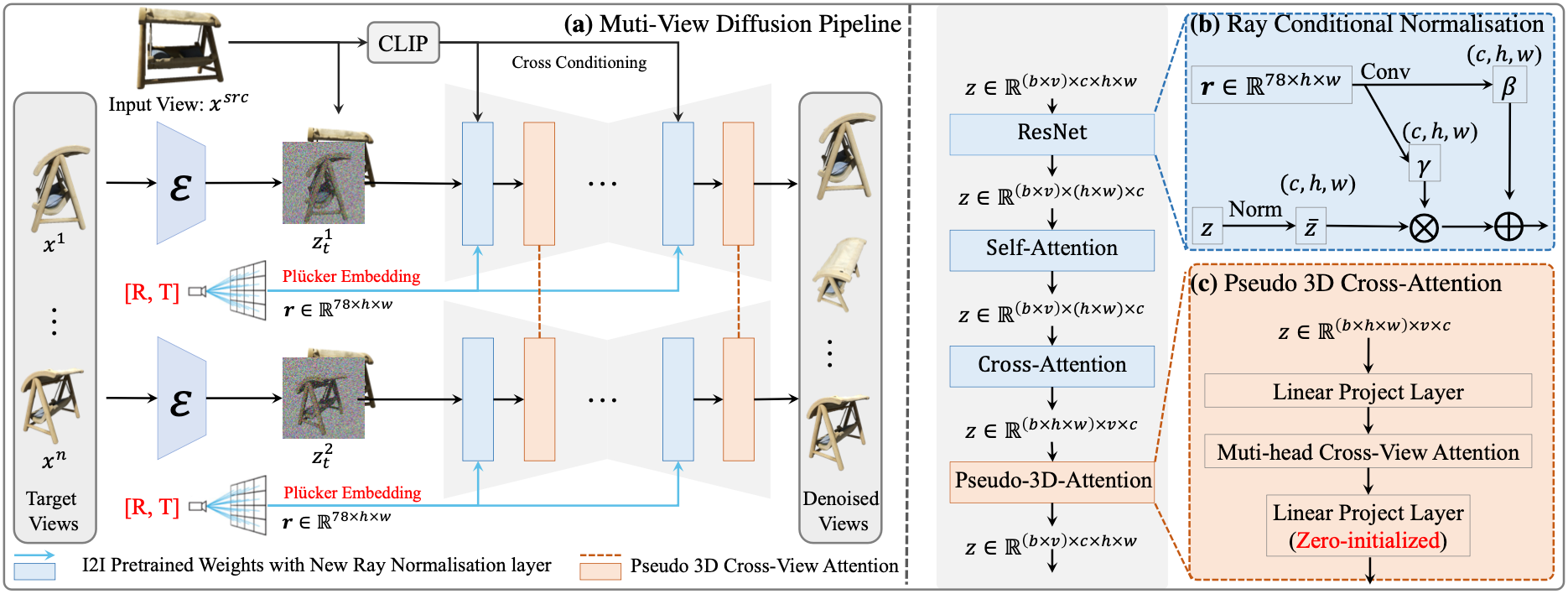
The overall pipeline of our Free3D. (a) Given a single source input image, the proposed architecture jointly predicts multiple target views, instead of processing them independently. To achieve a consistent novel view synthesis without the need for 3D representation, (b) we first propose a novel ray conditional normalization (RCN) layer, which uses a per-pixel oriented camera ray to module the latent features, enabling the model’s ability to capture more precise viewpoints. (c) A memory-friendly pseudo-3D cross-attention module is introduced to efficiently bridge information across multiple generated views. Note that, here the similarity score is only calculated across multiple views in temporal instead of spatial, resulting in a minimal computational and memory cost.
